robots.txtとは?【SEOの関係性と書き方を解説】




Webサイトを運用していると、robots.txtという用語を聞いたことがある方も多いはずです。
robots.txtは、主に検索エンジンのクローラーの動きを制御するために使用されています。
SEOの経験が少ない方であれば、以下のような疑問が生じると思います。
『robots.txtとは何?』
『設定方法はどうすればいい?』
今回のコラム記事では、Webサイトの運用やSEOの経験がまだ少ない担当者様に向けています。
robots.txtとSEOの関係性や、設定する際の注意点に関して解説をしています。
robots.txtとは
robots.txt(ロボッツ・テキスト)とは、検索エンジンのクローラーに対して、Webページのクロールを許可または拒否を伝えるためのテキストファイルです。
検索エンジンには、クローラーと呼ばれるWeb上のデータを収集するためのプログラムがあります。
クローラーが集めた情報は検索エンジンのデータベースに登録・分類され、検索アルゴリズムによって検索順位が決定されます。
robots.txtを設定すると、収集されたくないWebページをクローラーに伝えることが可能です。
また、サイト内検索結果ページや自動生成ページなど、クロールの必要性があまりないWebページに対して、robots.txtを使用するのも有効な方法です。
robots.txtとnoindexの違い
robots.txtとnoindexの大きな違いは、制御する対象が異なる点です。
robots.txtは検索エンジンのクローラーを制御するのに対して、noindexはインデックス自体を制御します。
noindexで指定されたWebページは検索結果に表示されませんが、Webページのクロールはされます。
反対に、robots.txtで指定されたWebページは基本的にクロールされません。
重要なWebページを効率よくクロールさせたい場合はrobots.txt、特定のWebページのインデックス登録をブロックしたい場合はnoindexと覚えておくとよいでしょう。
robots.txtとSEOの関係性
robots.txtを適切に設定することで、SEOの効果は期待できます。
robots.txtは検索エンジンのクローラーに対して、特定のWebページをクローリング(情報収集)しないように制御するために用いられます。
そうすることで、重要なWebページを中心にクロールするように促すことが可能です。
robots.txtをうまく活用することで、Webサイトで検索エンジンの評価を高めたいページに対するクロール頻度が上がり、SEOの効果をより早く得られる可能性があります。
特に100万ページを超えるような大規模サイトでは、robots.txtの重要性は高いです。
なぜなら、大規模サイトはWebページ数が多くて、クローラーの制御を行わなければWebサイトのページが効率よくクロールされないからです。
robots.txtでクローラーの制御を行い、重要なWebページを優先してクロールさせるように制御することが求められます。
robots.txtの書き方
robots.txtの基本的な書き方は、以下になります。
User-agent: *
Disallow:/abc/
Sitemap: https://example.com/sitemap.XML上記のように記述すると「https://example.com/abc/」で始まるURLはクロールしないよう、すべてのクローラーに対して情報を伝えることが可能です。
WordPress(ワードプレス)をお使いの方は、以下の内容でrobots.txtが自動生成されます。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/wp-sitemap.XML※WordPressの設定方法やお使いのテーマ、プラグインなどによって内容が異なる場合があります
次からは、robots.txtで使われる要素「User-Agent」「Disallow」「Allow」「Sitemap」の詳細を説明していきます。
User-Agent
User-Agent(ユーザーエージェント)は、クロールを制御するクローラー先の指定をする要素です。
ワイルドカード(*)を記述すると、すべてのクローラーが制御の対象となります。
User-agent: *特定のクローラーのみ巡回を制御したい場合は、制御したいクローラーのユーザーエージェントトークンを入力しましょう。
代表的なユーザーエージェントトークンは、次の表のとおりです。
| ユーザーエージェントトークン | 説明 |
|---|---|
| Googlebot | ・パソコン用Googlebot ・スマートフォン用Googlebot ・画像用Googlebot ・動画用Googlebot ・ニュース用Googlebot |
| Mediapartners-Google | ・AdSenseクローラー |
検索エンジンのGoogleが巡回しないように制御したい場合は、以下のように記述します。
User-agent: Googlebotほかにも、さまざまな種類のユーザーエージェントトークンが存在します。
くわしくは、Google検索セントラルの「Google クローラの概要(ユーザー エージェント)」で確認するとよいでしょう。
Disallow
Disallowは、クローラーが巡回しないURLを指定する要素です。
Webサイト全体、ディレクトリ、Webページ単位でクローラーの巡回を制御できます。
▼Webサイト全体で制御する
Disallow: /▼特定のディレクトリに対して制御する
Disallow: /abc/▼特定のWebページに対して制御する
Disallow: /abc.html以上のように記述することで、クロールを制限したいURLの設定をします。
記述方法の詳細は、Google検索セントラル「robots.txt の書き方、設定と送信方法」を参考にしてください。
Allow
Allowは、Disallowで指定したクロールしないWebページの中で、一部クロールさせたいWebページがある場合に用いられる要素です。
たとえば、Webサイト全体ではクロールしないように制限をしていて、特定のディレクトリのみクロールの対象としたいときには、次のように記述します。
Disallow: /
Allow: /abc/Sitemap
Sitemapは、XMLサイトマップがある場所のことです。
robots.txtにXMLサイトマップのURLを記載することで、クローラーがXMLサイトマップにアクセスしやすくなります。
robots.txtを作成する場合は、以下のようにXMLサイトマップのURLを記述しましょう。
Sitemap: http://example.com/sitemap.XML※URLは絶対パスで記述してください
ちなみに、robots.txtでは複数のSitemapを指定することも可能です。
大規模サイトのようにWebページの数が多くてXMLサイトマップを複数に分けている場合は、忘れずにrobots.txtにSitemapを記述しましょう。
robots.txtの設置方法
robots.txtを記述して作成できたら、FTPソフトを用いてrobots.txtをWebサーバーにアップロードします。
robots.txtの設置場所は、ドメインのルートディレクトリです。 サブディレクトリにrobots.txtを設置してもクローラーに認識されないので、注意してください。
robots.txtの確認方法
robots.txtの記述内容に誤りがあった場合は、クローラーの巡回を制御できません。
また、意図しないWebページをrobots.txtで設定すると、検索流入数に悪影響を及ぼす可能性があります。
そのため、記述した内容に誤りがないか、かならず確認してください。
robots.txtの内容を確認するには、Googleサーチコンソールの「robots.txtテスター」を使用しましょう。
出典:Google Search Console
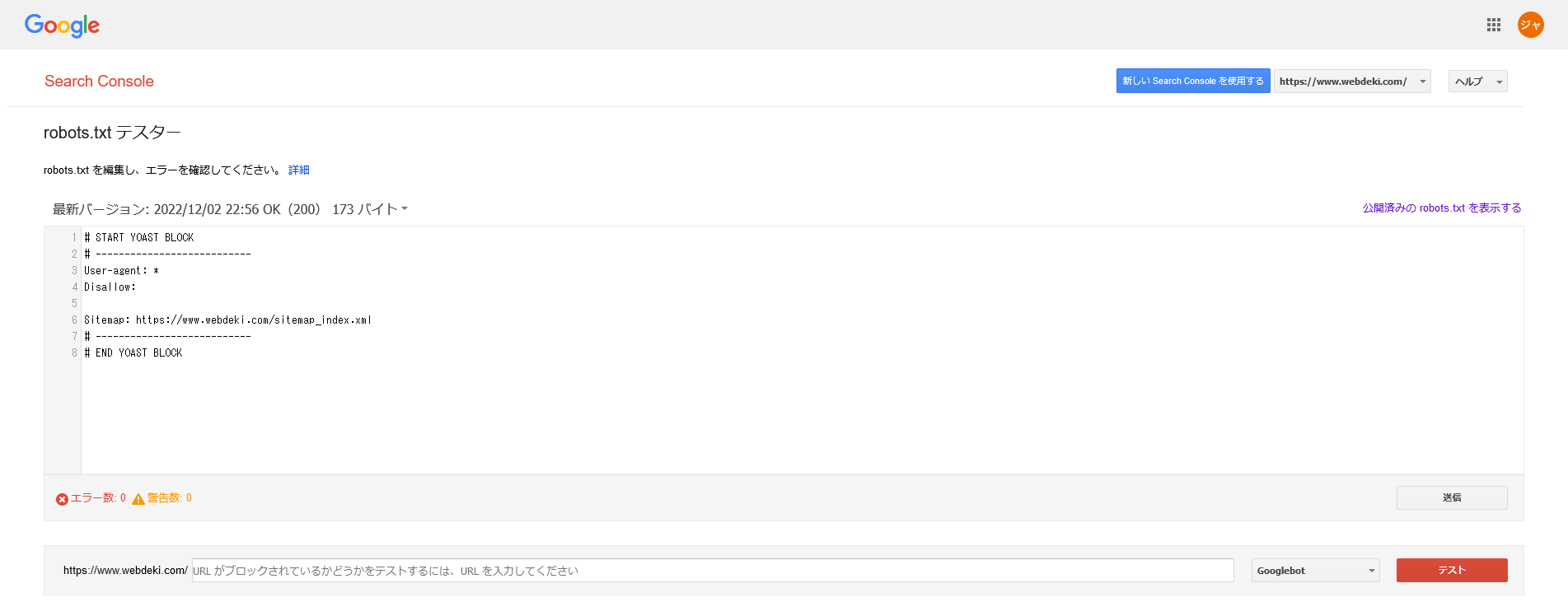
robots.txtテスターの入力部分に制御したURLを入力して、赤いボタンの「テスト」をクリックします。
Disallowの部分が赤いマーカーになって「ブロック済み」と表示されれば、正しく記述できています。
反対に、Disallowの部分が緑のマーカーになって「許可済み」と表示された場合は、robots.txtが正しく記述されていません。
robots.txtテスターを活用して、robots.txtの動作確認をしましょう。
robots.txtを設定する際の注意点
robots.txtを設定する際は、以下の注意点を確認したうえで作業を行いましょう。
- すべてのクローラーがrobots.txtに従うとは限らない
- robots.txtを指定してもユーザーは閲覧できる
- robots.txtとnoindexの併用はできるだけ避ける
- ファイルの作成や設置には注意する
- 文法チェックをする
- robots.txtの反映には時間がかかる
これらの内容に関して、くわしく解説します。
すべてのクローラーがrobots.txtに従うとは限らない
robots.txtは検索エンジンのクローラーを制御するファイルですが、すべてのクローラーがrobots.txtの内容に従うとは限りません。
Googleなどのクローラーは問題ないかもしれませんが、一部のクローラーではrobots.txtの内容を無視して強制的にクロールする可能性があります。
robots.txtには強制力がありません。
Webページのクロールをブロックしたい場合は「.htaccess」を利用してアクセス制限をかける方法が確実です。
robots.txtを指定してもユーザーは閲覧できる
特定のWebページをrobots.txtに指定しても、ユーザーはそのWebページを閲覧できます。
Webページの閲覧方法を挙げると、Webサイトの内部リンクもしくは外部リンクからたどる、URLを直接入力する、検索からくる(インデックス登録のWebページに限る)といった方法などです。
ユーザーが特定のWebページにアクセスできないように制限をかけたい場合は、次の対策を行います。
- 基本認証でアクセス制限をかける
- ログインしないと閲覧できないようにする
- テストサーバーを使用する
特定のWebページをユーザーに見られないように制御したい場合は、上記の対策を実施しましょう。
robots.txtとnoindexの併用はできるだけ避ける
robots.txtで指定したWebページに、noindexを設定するのはできるだけ避けましょう。
robots.txtとnoindexの併用は可能ですが、noindexがうまく働かないかもしれません。
たとえば、noindexとrobots.txtの設定をしているインデックス済みのWebページがあるとします。
robots.txtが原因で、クローラーがWebページにうまくクロールできなくなり、検索結果から削除されない可能性があります。
インデックス登録済みのWebページを削除したい場合は、先にnoindexを設定しておきましょう。
検索結果からWebページの削除が確認できたら、robots.txtでクロールの制御を行いましょう。
ファイルの作成や設置には注意する
robots.txtの作成や設置で間違うと、クローラーの制御がうまく行われません。
Webサイトにrobots.txtを設置する前には、以下のポイントを確認しておきましょう。
- Disallowの内容は合っているか
- ファイル名は「robots.txt」で合っているか
- ドメインのルートディレクトリ上にrobots.txtを設置しているか
文法チェックをする
作成したrobots.txtをWebサーバーにアップしたあと、robots.txtの文法にミスがないかチェックをしましょう。
robots.txtの文法チェックは、Googleサーチコンソールの「robots.txtテスター」が便利です。
希望に沿ったクローラーの動きをしてもらうためにも、robots.txtテスターを使った文法チェックはかならずしてください。
robots.txtの反映には時間がかかる
robots.txtをWebサーバーにアップロードしたからといって、すぐにクローラーの制御が反映されるわけではありません。
robots.txtが反映されるまでの目安は、1週間から2週間ほどです。
計画を立てて、robots.txtの作成や設置をするとよいでしょう。
まとめ
今回は、robots.txtの定義や書き方、設定する際の注意点などを解説しました。
robots.txtに関して、重要なポイントは以下のとおりです。
- robots.txtは、検索エンジンのクローラーに対して特定のWebページをクロールしないように制御するファイル
- robots.txtとnoindexの違いを理解し、正しく使い分けること
- 今回のコラム記事で説明した書き方、設定時の注意点などを確認して作業を行う
robots.txtを適切に設定することで、検索エンジンのクローラーに対して重要なWebページを中心にクロールするように促すことができます。
その結果、Webサイトで検索エンジンの評価を高めたいページに対するクロールの頻度が上がり、SEOの効果をより早く得られる可能性があります。
特に100万ページを超えるような大規模サイトの場合は、robots.txtで適切にクローラーの制御を行うことが理想です。
robots.txtをまだ設定していない場合は、今回のコラム記事の内容を参考に設定することをおすすめします。





まずは無料でご相談ください。
お問い合わせ・ご相談や、公開後の修正依頼などに関しては、いずれかの方法にてお問い合わせください。
※年末年始・土日祝は定休日となります
※受付時間 9:00~17:30
